Running Spark on Top of a Hadoop YARN Cluster
Traducciones al EspañolEstamos traduciendo nuestros guías y tutoriales al Español. Es posible que usted esté viendo una traducción generada automáticamente. Estamos trabajando con traductores profesionales para verificar las traducciones de nuestro sitio web. Este proyecto es un trabajo en curso.
Spark is a general purpose cluster computing system. It can deploy and run parallel applications on clusters ranging from a single node to thousands of distributed nodes. Spark was originally designed to run Scala applications, but also supports Java, Python and R.



Spark can run as a standalone cluster manager, or by taking advantage of dedicated cluster management frameworks like Apache Hadoop YARN or Apache Mesos.
Before You Begin
Follow our guide on how to install and configure a three-node Hadoop cluster to set up your YARN cluster. The master node (HDFS NameNode and YARN ResourceManager) is called node-master and the slave nodes (HDFS DataNode and YARN NodeManager) are called node1 and node2.
Run the commands in this guide from node-master unless otherwise specified.
Be sure you have a
hadoopuser that can access all cluster nodes with SSH keys without a password.Note the path of your Hadoop installation. This guide assumes it is installed in
/home/hadoop/hadoop. If it is not, adjust the path in the examples accordingly.Run
jpson each of the nodes to confirm that HDFS and YARN are running. If they are not, start the services with:start-dfs.sh start-yarn.sh
NoteThis guide is written for a non-root user. Commands that require elevated privileges are prefixed withsudo. If you’re not familiar with thesudocommand, see the Users and Groups guide.
Download and Install Spark Binaries
Spark binaries are available from the Apache Spark download page. Adjust each command below to match the correct version number.
Get the download URL from the Spark download page, download it, and uncompress it.
For Spark 2.2.0 with Hadoop 2.7 or later, log on
node-masteras thehadoopuser, and run:cd /home/hadoop wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz tar -xvf spark-2.2.0-bin-hadoop2.7.tgz mv spark-2.2.0-bin-hadoop2.7 sparkAdd the Spark binaries directory to your
PATH. Edit/home/hadoop/.profileand add the following line:For Debian/Ubuntu systems:
- File: /home/hadoop/.profile
1PATH=/home/hadoop/spark/bin:$PATH
For RedHat/Fedora/CentOS systems:
- File: /home/hadoop/.profile
1pathmunge /home/hadoop/spark/bin
Integrate Spark with YARN
To communicate with the YARN Resource Manager, Spark needs to be aware of your Hadoop configuration. This is done via the HADOOP_CONF_DIR environment variable. The SPARK_HOME variable is not mandatory, but is useful when submitting Spark jobs from the command line.
Edit the hadoop user profile
/home/hadoop/.profileand add the following lines:- File: /home/hadoop/.profile
1 2 3export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop export SPARK_HOME=/home/hadoop/spark export LD_LIBRARY_PATH=/home/hadoop/hadoop/lib/native:$LD_LIBRARY_PATH
Restart your session by logging out and logging in again.
Rename the spark default template config file:
mv $SPARK_HOME/conf/spark-defaults.conf.template $SPARK_HOME/conf/spark-defaults.confEdit
$SPARK_HOME/conf/spark-defaults.confand setspark.mastertoyarn:- File: $SPARK_HOME/conf/spark-defaults.conf
spark.master yarn
Spark is now ready to interact with your YARN cluster.
Understand Client and Cluster Mode
Spark jobs can run on YARN in two modes: cluster mode and client mode. Understanding the difference between the two modes is important for choosing an appropriate memory allocation configuration, and to submit jobs as expected.
A Spark job consists of two parts: Spark Executors that run the actual tasks, and a Spark Driver that schedules the Executors.
Cluster mode: everything runs inside the cluster. You can start a job from your laptop and the job will continue running even if you close your computer. In this mode, the Spark Driver is encapsulated inside the YARN Application Master.
Client mode the Spark driver runs on a client, such as your laptop. If the client is shut down, the job fails. Spark Executors still run on the cluster, and to schedule everything, a small YARN Application Master is created.
Client mode is well suited for interactive jobs, but applications will fail if the client stops. For long running jobs, cluster mode is more appropriate.
Configure Memory Allocation
Allocation of Spark containers to run in YARN containers may fail if memory allocation is not configured properly. For nodes with less than 4G RAM, the default configuration is not adequate and may trigger swapping and poor performance, or even the failure of application initialization due to lack of memory.
Be sure to understand how Hadoop YARN manages memory allocation before editing Spark memory settings so that your changes are compatible with your YARN cluster’s limits.
NoteSee the memory allocation section of the Install and Configure a 3-Node Hadoop Cluster guide for more details on managing your YARN cluster’s memory.
Give Your YARN Containers Maximum Allowed Memory
If the memory requested is above the maximum allowed, YARN will reject creation of the container, and your Spark application won’t start.
Get the value of
yarn.scheduler.maximum-allocation-mbin$HADOOP_CONF_DIR/yarn-site.xml. This is the maximum allowed value, in MB, for a single container.Make sure that values for Spark memory allocation, configured in the following section, are below the maximum.
This guide will use a sample value of 1536 for yarn.scheduler.maximum-allocation-mb. If your settings are lower, adjust the samples with your configuration.
Configure the Spark Driver Memory Allocation in Cluster Mode
In cluster mode, the Spark Driver runs inside YARN Application Master. The amount of memory requested by Spark at initialization is configured either in spark-defaults.conf, or through the command line.
From spark-defaults.conf
Set the default amount of memory allocated to Spark Driver in cluster mode via
spark.driver.memory(this value defaults to1G). To set it to512MB, edit the file:- File: $SPARK_HOME/conf/spark-defaults.conf
spark.driver.memory 512m
From the Command Line
Use the
--driver-memoryparameter to specify the amount of memory requested byspark-submit. See the following section about application submission for examples.Note
Values given from the command line will override whatever has been set inspark-defaults.conf.
Configure the Spark Application Master Memory Allocation in Client Mode
In client mode, the Spark driver will not run on the cluster, so the above configuration will have no effect. A YARN Application Master still needs to be created to schedule the Spark executor, and you can set its memory requirements.
Set the amount of memory allocated to Application Master in client mode with spark.yarn.am.memory (default to 512M)
- File: $SPARK_HOME/conf/spark-defaults.conf
spark.yarn.am.memory 512m
This value can not be set from the command line.
Configure Spark Executors’ Memory Allocation
The Spark Executors’ memory allocation is calculated based on two parameters inside $SPARK_HOME/conf/spark-defaults.conf:
spark.executor.memory: sets the base memory used in calculationspark.yarn.executor.memoryOverhead: is added to the base memory. It defaults to 7% of base memory, with a minimum of384MB
NoteMake sure that Executor requested memory, including overhead memory, is below the YARN container maximum size, otherwise the Spark application won’t initialize.
Example: for spark.executor.memory of 1Gb , the required memory is 1024+384=1408MB. For 512MB, the required memory will be 512+384=896MB
To set executor memory to 512MB, edit $SPARK_HOME/conf/spark-defaults.conf and add the following line:
- File: $SPARK_HOME/conf/spark-defaults.conf
spark.executor.memory 512m
How to Submit a Spark Application to the YARN Cluster
Applications are submitted with the spark-submit command. The Spark installation package contains sample applications, like the parallel calculation of Pi, that you can run to practice starting Spark jobs.
To run the sample Pi calculation, use the following command:
spark-submit --deploy-mode client \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.2.0.jar 10
The first parameter, --deploy-mode, specifies which mode to use, client or cluster.
To run the same application in cluster mode, replace --deploy-mode clientwith --deploy-mode cluster.
Monitor Your Spark Applications
When you submit a job, Spark Driver automatically starts a web UI on port 4040 that displays information about the application. However, when execution is finished, the Web UI is dismissed with the application driver and can no longer be accessed.
Spark provides a History Server that collects application logs from HDFS and displays them in a persistent web UI. The following steps will enable log persistence in HDFS:
Edit
$SPARK_HOME/conf/spark-defaults.confand add the following lines to enable Spark jobs to log in HDFS:- File: $SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://node-master:9000/spark-logs
Create the log directory in HDFS:
hdfs dfs -mkdir /spark-logsConfigure History Server related properties in
$SPARK_HOME/conf/spark-defaults.conf:- File: $SPARK_HOME/conf/spark-defaults.conf
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider spark.history.fs.logDirectory hdfs://node-master:9000/spark-logs spark.history.fs.update.interval 10s spark.history.ui.port 18080
You may want to use a different update interval than the default
10s. If you specify a bigger interval, you will have some delay between what you see in the History Server and the real time status of your application. If you use a shorter interval, you will increase I/O on the HDFS.Run the History Server:
$SPARK_HOME/sbin/start-history-server.shRepeat steps from previous section to start a job with
spark-submitthat will generate some logs in the HDFS:Access the History Server by navigating to http://node-master:18080 in a web browser:


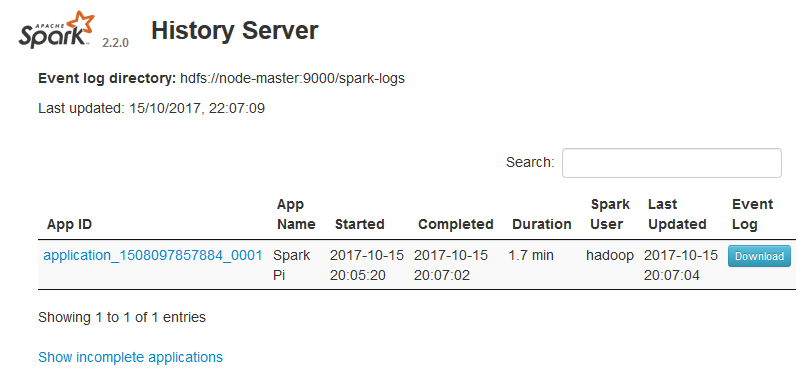
Run the Spark Shell
The Spark shell provides an interactive way to examine and work with your data.
Put some data into HDFS for analysis. This example uses the text of Alice In Wonderland from the Gutenberg project:
cd /home/hadoop wget -O alice.txt https://www.gutenberg.org/files/11/11-0.txt hdfs dfs -mkdir inputs hdfs dfs -put alice.txt inputsStart the Spark shell:
spark-shell var input = spark.read.textFile("inputs/alice.txt") // Count the number of non blank lines input.filter(line => line.length()>0).count()
The Scala Spark API is beyond the scope of this guide. You can find the official documentation on Official Apache Spark documentation.
Where to Go Next ?
Now that you have a running Spark cluster, you can:
- Learn any of the Scala, Java, Python, or R APIs to create Spark applications from the Apache Spark Programming Guide
- Interact with your data with Spark SQL
- Add machine learning capabilities to your applications with Apache MLib
More Information
You may wish to consult the following resources for additional information on this topic. While these are provided in the hope that they will be useful, please note that we cannot vouch for the accuracy or timeliness of externally hosted materials.
This page was originally published on